이전 블로그에서는 Producer 생성하는 실습을 진행하였는데 이제는 데이터를 받는 입장인 Consumer 관련 내용이다. 환경은 이전과 동일하다. Consumer 생성의 기본적인 코드(Auto Commit = false)는 이미지로 대처하고 (Auto commit = ture)로 설정하는 코드부터 진행하였다. 개인적으로 Consumer에서 공부할 부분이 조금 더 많았던 것 같다.
1. 가장 기본적인 Consumer


2. Auto Commit test
configs.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, true);
package com.tacademy;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.Arrays;
import java.util.Properties;
public class ConsumerWithAutoCommit {
private static String TOPIC_NAME = "test";
private static String GROUP_ID = "testgroup";
private static String BOOTSTRAP_SERVERS = "{aws ec2 public ip}:9092";
public static void main(String[] args) {
Properties configs = new Properties();
configs.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
configs.put(ConsumerConfig.GROUP_ID_CONFIG, GROUP_ID);
configs.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
configs.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
configs.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, true);
configs.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, 60000);
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(configs);
consumer.subscribe(Arrays.asList(TOPIC_NAME));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1));
for (ConsumerRecord<String, String> record : records) {
System.out.println(record.value());
}
}
}
}- configs.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, 60000);
60초 마다 컨슈머가 어디까지 읽었는지 Broker에게 알려주는 것.
한 번 출력을 했어도 60초 이내 다시 컨슈머를 재실행시키면 한번 더 데이터가 출력된다. → 데이터 중복 처리 발생
Consumer commit
enable.auto.commit=true
- 일정 간격, poll() 메서드 호출 시 자동 commit
- 속도가 가장 빠르다.
- 중복 또는 유실이 발생할 수 있다.
컨슈머가 강제로 종료되거나 셧다운될 때 데이터가 중복처리될 수 있다.
그렇다면 데이터 중복을 막을 수 있는 방법은?
- auto commit을 사용하되 컨슈머가 죽지 않도록 한다 → 불가능. 서버/애플리케이션은 언제든지 죽을 수 있다.
- auto.commit을 사용하지 않는다.
Kafka consumer의 commitSync(), commitAsync() 사용
enable.auto.commit=false
1) commitSync() : 동기커밋

- consumerRecord 처리 순서를 보장함.
- 속도가 가장 느림.
- poll() 메서드로 반환된 ConsumerRecord이 마지막 offset을 커밋
- Map<TopicPartition, OffsetAndMetadata>을 통해 오프셋 지정 커밋 가능

2) commitAsync() : 비동기 커밋

- 동기 커밋보다 빠름.
- 중복이 발생할 수 있음.
일시적인 통신 문제로 이전 offset보다 이후 offset이 먼저 커밋될 때
처리 순서가 중요한 서비스 (주문, 재고관리 등)에서는 사용 제한
Consumer rebalance
컨슈머 그룹의 파티션 소유권이 변경될 때 일어나는 현상
When: consumer.close() 호출 시, consumer의 세션 끊겼을 때, 컨슈머-파티션 할당이 변경될 때
- 리밸런스를 하는 동안 일시적으로 메시지를 가져올 수 있다.
- 리밸런스 발생 시 데이터 유실/중복 발생 가능성 있다.
- commitSync() 또는 추가적인 방법(unique key)으로 데이터 유실/중복 방지
Consumer wakeup

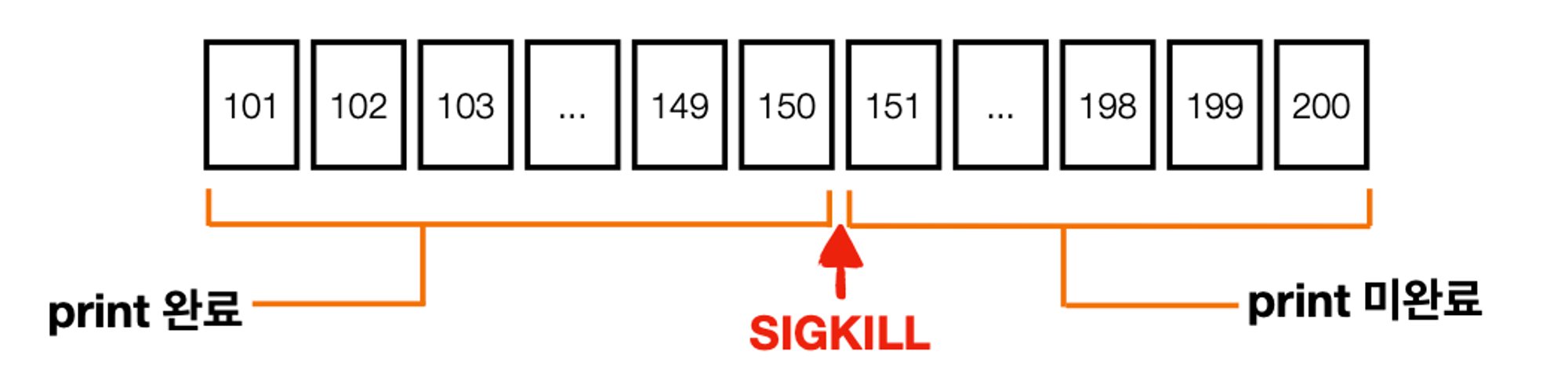
SIGKILL 로 인한 중복 처리 발생에서 wakeup 동작 예시
(1) poll() 호출 : records 100개 반환. offset 101 ~200
(2) records loop 구문 수행
(3) record.value() system 150 오프셋 print 중 SIGKILL 호출
101~150번 오프셋 처리 완료. 151~200 오프셋 미처리
(4) offset 200 커밋 불가
브로커에는 100번 오프셋이 마지막 커밋
컨슈머 재시작하면 다시 오프셋 101부터 처리 시작. → 101~150번 오프셋 중복 처리
코드 예시

- wakeup() 을 통한 graceful shutdown이 필수
SIGKILL(9)는 프로세스 강제 종료로 커밋 불가 → 중복/유실 발생
SIGTERM을 통한 sutdown signal로 kill하여 처리한 데이터 커밋 필요
3. Consumer Multiple Thread
한개의 프로세스에 여러개의 스레드 생성
안전하게 종료하기 위해 shutdown, WakeupException 중요함. 실제 코드 개발할 때 유의하기!
ConsumerWithMultiThread 코드
package com.tacademy;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.util.ArrayList;
import java.util.List;
import java.util.Properties;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class ConsumerWithMultiThread {
private static String TOPIC_NAME = "test";
private static String GROUP_ID = "testgroup";
private static String BOOTSTRAP_SERVERS = "{브로커 ip}:9092";
private static int CONSUMER_COUNT = 3;
private static List<ConsumerWorker> workerThreads = new ArrayList<>();
public static void main(String[] args) {
Runtime.getRuntime().addShutdownHook(new ShutdownThread());
Properties configs = new Properties();
configs.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
configs.put(ConsumerConfig.GROUP_ID_CONFIG, GROUP_ID);
configs.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
configs.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
configs.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false);
ExecutorService executorService = Executors.newCachedThreadPool();
for (int i = 0; i < CONSUMER_COUNT; i++) {
ConsumerWorker worker = new ConsumerWorker(configs, TOPIC_NAME, i);
workerThreads.add(worker);
executorService.execute(worker);
}
}
static class ShutdownThread extends Thread {
public void run() {
workerThreads.forEach(ConsumerWorker::shutdown);
System.out.println("Bye");
}
}
}newCachedTreadPool : 스레드 완료되면 스스로 죽음
ConsumerWorker 코드
package com.tacademy;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.errors.WakeupException;
import java.time.Duration;
import java.util.Arrays;
import java.util.Properties;
public class ConsumerWorker implements Runnable {
private Properties prop;
private String topic;
private String threadName;
private KafkaConsumer<String, String> consumer;
ConsumerWorker(Properties prop, String topic, int number) {
this.prop = prop;
this.topic = topic;
this.threadName = "consumer-thread-" + number;
}
@Override
public void run() {
consumer = new KafkaConsumer<>(prop);
consumer.subscribe(Arrays.asList(topic));
try {
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1));
for (ConsumerRecord<String, String> record : records) {
System.out.println(threadName + " >> " + record.value());
}
consumer.commitSync();
}
} catch (WakeupException e) {
System.out.println(threadName + " trigger WakeupException");
} finally {
consumer.commitSync();
consumer.close();
}
}
public void shutdown() {
consumer.wakeup();
}
}
실행결과
3개의 스레드가 번갈아가면서 데이터 처리함. 터미널에서 jps 명령어로 ConsumerWithMultiThread 실행중인 것을 확인할 수 있음.


Trouble Shooting
1. 카프카가 제대로 동작하고 있지 않았을 시에 마주할 수 있는 에러

이럴 때는 인스턴스로 접속해서 jps 확인 후에 브로커, 카프카 서버 순서대로 다시 실행시키면 된다.
2. comsumer, producer 에서 코드 실행 시 broker와의 connection error가 났으면 먼저 broker가 잘 작동하고 있는지 확인. 인스턴스를 오랫동안 켜두면 왜인지 모르게 broker가 실행 중지 상태로 변경되었었음.
'Open source' 카테고리의 다른 글
| [ Virtualization ] 가상화 개념과 종류 (VM, Hypervisor) (0) | 2024.03.06 |
|---|---|
| Kafka Producer 실습 - kafka (5) (0) | 2024.03.02 |
| Kafka Consumer & lag 모니터링 - kafka(4) (0) | 2024.02.28 |
| Kafka Broker, Replication, ISR - kafka(3) (0) | 2024.02.22 |
| Kafka Producer - kafka(2) (0) | 2024.02.22 |