Open source
Kafka Producer - kafka(2)
jogaknabi_1023
2024. 2. 22. 22:23
Kafka Producer
Producer role
- Topic에 해당하는 메시지를 생성
- 특정 Topic으로 데이터를 publish
- 처리 실패/재시도
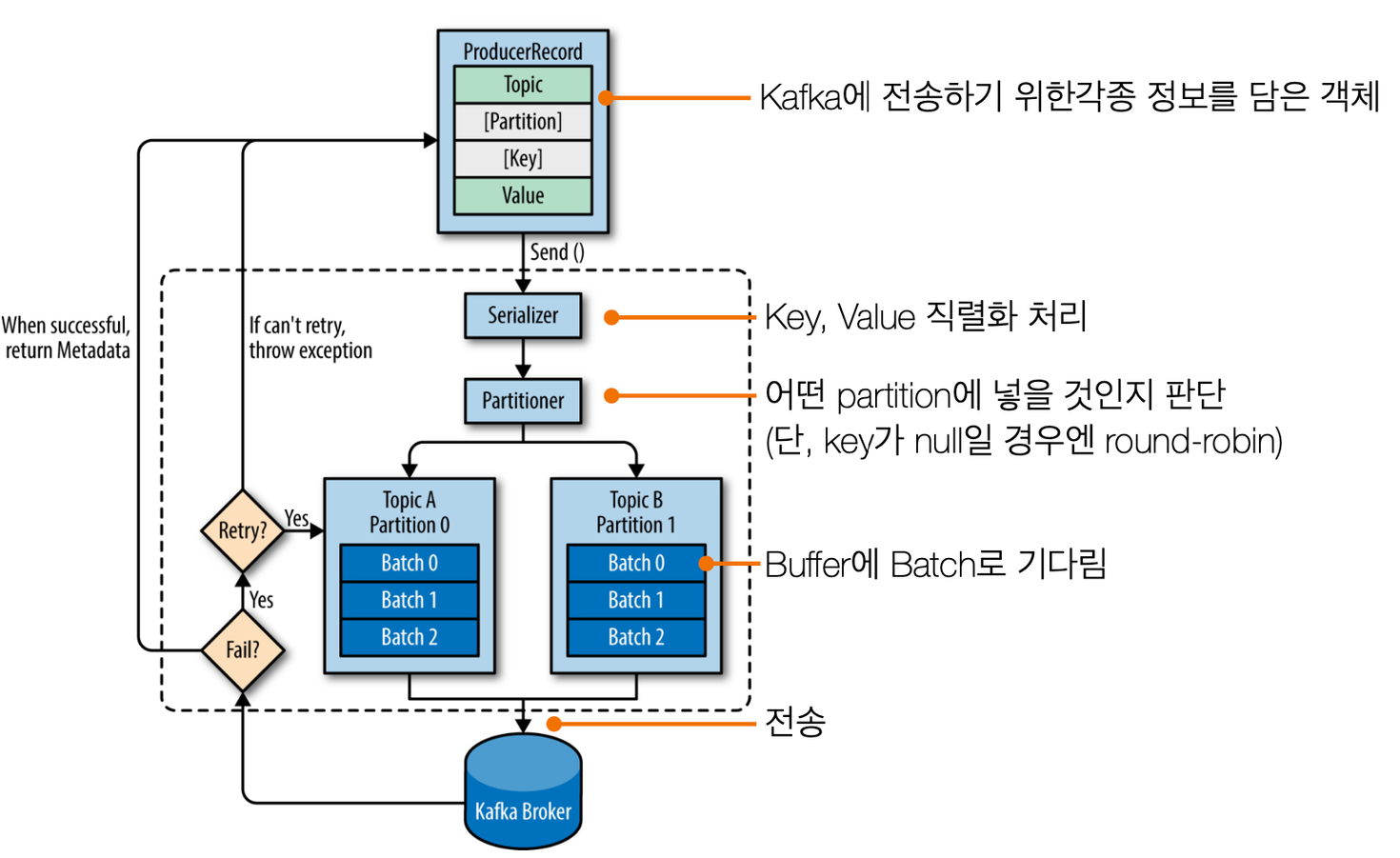
Kafka Producer 구조
라이브러리 추가 필수
기본적으로 자바 라이브러리 사용. 라이브러리 관리 도구인 gradle 이나 maven 사용

Producer 코드 예제

- 자바 프로퍼티 객체를 통해 프로듀서의 설정 정의
- 부트스트랩 서버 설정을 로컬 호스트의 카프카를 바라보도록 설정
- 카프카 브로커의 주소목록은 되도록 2개 이상의 ip와 port를 설정하도록 권장
- key와 value에 대해 스트링시리얼라이저로 직렬화. (시리얼라이저는 key 혹은 value를 직렬화하기 위해 사용된다. Byte array, String, Integer 시리얼라이즈를 사용할 수 있다.)
여기서 key는 메시지를 보내면 토픽의 파티션이 지정될 때 사용된다.
KafkaProducer<String, String > producer = new KafkaProducer < String, String > (configs) ;
ProducerRecord record = new ProducerRecoed < String, String > ("click_log", "login");
producer.send(record);
producer.close();- 설정한 프로퍼티로 카프카 프로듀서 인스턴스를 만든다.
- 전송할 객체는 어떻게 만들까?위의 코드에서는 click_log 토픽에 login 이라는 value를 보낸다. 만약 key를 포함하고 싶다면 ("click_log", “1”, "login") 프로듀서 레코드를 선언하면 된다.
- 카프카 클라이언트에서는 ProducerRecord 클래스를 제공한다. ProducerRecord 인스턴스를 생성할 때 어느 토픽에 넣을 것인지 어떤 key 와 value를 담을 것인지 선언할 수 있다.
- send() 메서드의 파라미터로 ProducerRecord를 넣으면 전송이 이루어지게 됨. click_log 토픽에 login value가 들어가게 된다.
- 그리고 전송이 완료되면 close() 메서드를 통해 프로듀서를 종료한다.
어떻게 producer가 토픽의 파티션에 들어갈까?
1) key=null 인 경우

- key 가 null인 데이터를 파티션이 1개인 토픽에 보내면 하나의 파티션에 차례대로 쌓이게 된다.
- 만약 파티션이 한 개 더 늘어나면? (key=null)
- 데이터가 라운드 로빈으로 2개의 파티션의 차례대로 쌓이게 됨.
2) key가 null이 아닌 경우
카프카는 key를 특정한 hash값으로 변경시켜 파티션과 1:1 매칭을 시킨다.

→ 결과 : 각 파티션에 동일 key의 value만 쌓이게 된다. 여기서 새로운 파티션을 추가하는 순간 key와 파티션의 매칭이 깨지기 때문에 key-파티션의 연결은 보장되지 않는다.
Producer Options
💡 필수옵션
bootstrap.servers : 카프카 클러스터에 연결하기 위한 브로커 목록
key.serializer : 메시지 키 직렬화에 사용되는 클래스
value.serializer : 메시지 값을 직렬화 하는데 사용되는 클래스
💡 선택옵션
acks : 레코드 전송 신뢰도 조절
comression.type : snappy, gzip, Iz4 중 하나로 압축하여 전송
retries : 클러스터 장애에 대응하여 메시지 전송을 재시도하는 횟수
buffer.memory : 브로커에 전송될 메시지의 버퍼로 사용될 메모리 양
batch.size : 여러 데이터를 함께 보내기 위한 레코드 크기
linger.ms : 현재의 배치를 전송하기 전까지 기다리는 시간
client.id : 어떤 클라이언트인지 구별하는 식별자